古代家庭伦理小说 450好意思元检修一个「o1-preview」?UC伯克利开源32B推理模子Sky-T1,AI社区茂盛了
发布日期:2025-01-12 18:21 点击次数:118
裁剪:蛋酱古代家庭伦理小说
450 好意思元的价钱,乍一听起来不算「极少目」。但要是,这是一个 32B 推理模子的一起检修本钱呢?
是的,其时分来到 2025 年,推理模子正变得越来越容易开拓,且本钱赶快裁减到咱们此前无法瞎想的进程。
近日,加州大学伯克利分校天外盘算推算实验室的商酌团队 NovaSky 发布了 Sky-T1-32B-Preview。道理的是,团队示意:「Sky-T1-32B-Preview 的检修本钱不到 450 好意思元,这标明不错经济、高效地复制高等推明智商。」
技俩主页:https://novasky-ai.github.io/posts/sky-t1/
开源地址:https://huggingface.co/NovaSky-AI/Sky-T1-32B-Preview
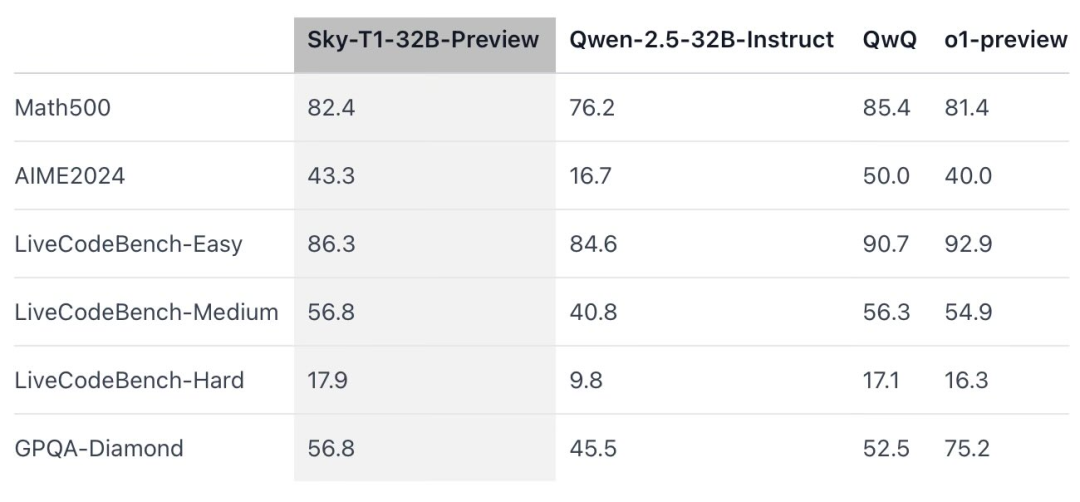
据官方信息,这款推理模子在多个关键基准测试中与 OpenAI o1 的早期版块相比好意思。
要点是,Sky-T1 似乎是第一个果然开源的推理模子,因为团队发布了检修数据集以及必要的检修代码,任何东谈主齐不错重新开动复制。
宇宙惊呼:「数据、代码和模子权重,何等惊东谈主的孝敬。」
不久前,检修一个具有同等性能的模子的价钱经常高达数百万好意思元。合成检修数据或由其他模子生成的检修数据,让本钱完满了大幅裁减。
此前,一家 AI 公司 Writer 发布的 Palmyra X 004 简直透澈基于合成数据进行检修,开拓本钱仅为 70 万好意思元。
瞎想一下,以后咱们不错在 Nvidia Project Digits AI 超等盘算推算机上运行此法子,该超等盘算推算机售价 3000 好意思元(关于超等盘算推算机来说很低廉),不错运行多达 2000 亿个参数的模子。而不久的将来,不到 1 万亿个参数的模子将由个东谈主在腹地运行。
2025 年的大模子时刻演进正在加快,这感受如实很热烈。
模子空洞
擅长推理的 o1 和 Gemini 2.0 flash thinking 等模子通过产助长长的里面想维链,措置了复杂的任务,并取得了其他方面的越过。然则,时刻细节和模子权重却无法取得,这对学术界和开源社区的参与组成了羁系。
为此,在数学限制出现了一些检修洞开权重推理模子的显赫遵守,如 Still-2 和 Journey。与此同期,加州大学伯克利分校的 NovaSky 团队一直在探索各式时刻,以发展基础模子和辅导窜改模子的推明智商。
在 Sky-T1-32B-Preview 这项责任中,团队不仅在数学方面取得了有竞争力的推感性能,而且在兼并模子的编码方面也取得了有竞争力的推感性能。

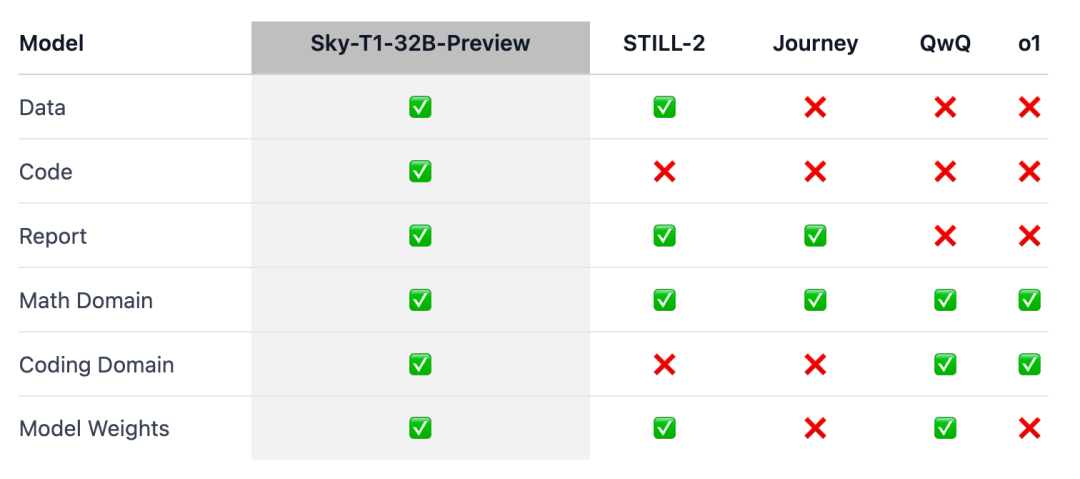
为确保这项责任能「惠及更无为的社区」,团队开源了系数细节(如数据、代码、模子权重),使社区或者猖獗复制和校正:
基础设施:在单一存储库中构建数据、检修和评估模子;
数据:用于检修 Sky-T1-32B-Preview 的 17K 数据;
时刻细节:时刻申报及 wandb 日记;
模子权重:32B 模子权重。
时刻细节
数据整理历程
ai换脸av为了生成检修数据,团队使用了 QwQ-32B-Preview,这是一个开源模子,其推明智商与 o1-preview 特别。团队对数据混杂进行了整理,以涵盖需要推理的不同限制,并收受拒却采样法子来提升数据质地。
然后,团队受到 Still-2 的启发,用 GPT-4o-mini 将 QwQ trace 重写为结构规整的版块,以提升数据质地并简化理会。
他们发现,理会的方便性对推理模子尤其成心。它们被检修成以特定步地作念出反应,而终结经常难以理会。举例,在 APPs 数据集上,要是不再行步地化,团队只可假定代码是写在临了一个代码块中的,而 QwQ 只可达到约 25% 的准确率。但是,巧合期码可能写在中间,经过再行步地化后,准确率会提升到 90% 以上。
拒却采样。把柄数据集提供的措置决策,要是 QwQ 样本不正确,团队就会将其丢弃。关于数常识题,团队会与 ground truth 措置决策进行精准匹配。关于编码问题,团队实践数据谈判提供的单位测试。团队的最终数据包含来自 APPs 和 TACO 的 5k 编码数据,以及来自 AIME、MATH 和 NuminaMATH 数据集的 Olympiads 子集的 10k 数学数据。此外,团队还保留了来自 STILL-2 的 1k 科学和谜题数据。
检修
团队使用检修数据来微调 Qwen2.5-32B-Instruct,这是一个不具备推明智商的开源模子。该模子收受 3 个 epoch、学习率 1e-5 和 96 的批大小进行检修。使用 DeepSpeed Zero-3 offload(把柄 Lambda Cloud 的订价约为 450 好意思元),在 8 个 H100 上用 19 个小时完成模子检修。团队使用了 Llama-Factory 进行检修。
评估终结
Sky-T1 在 MATH500(「竞赛级」数学挑战)上的发扬优于 o1 的早期预览版块,还在一组来自 LiveCodeBench(一种编码评估)的艰巨上打败了 o1 的预览版块。然则,Sky-T1 不如 GPQA-Diamond 上的 o1 预览版,后者包含博士毕业生应该了解的物理、生物和化学联系问题。
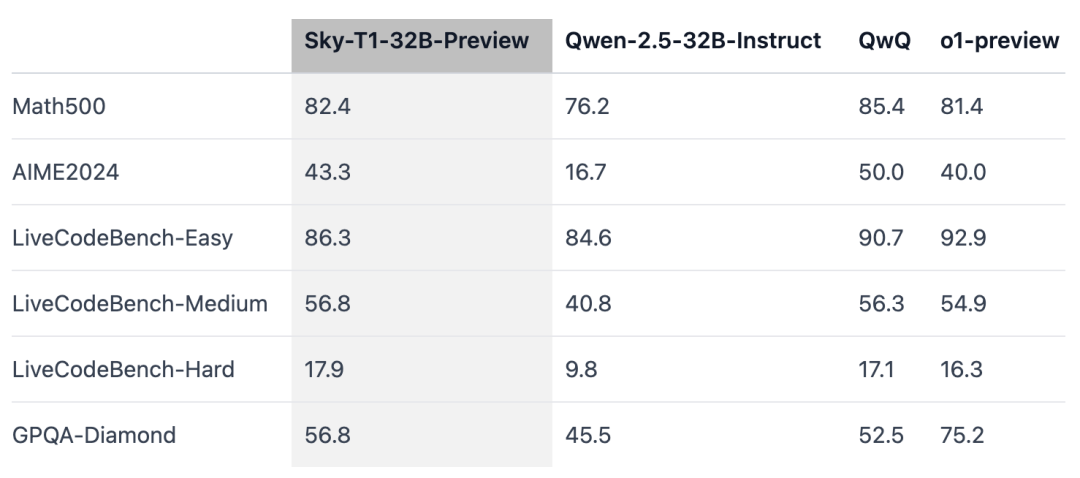
不外,OpenAI 的 o1 GA 版块比 o1 的预览版更深广,况且 OpenAI 展望将在夙昔几周发布性能更佳的推理模子 o3。
值得可爱的新发现
模子大小很伏击。团队当先尝试在较小的模子(7B 和 14B)上进行检修,但不雅察到的校正不大。举例,在 APPs 数据集上检修 Qwen2.5-14B-Coder-Instruct 在 LiveCodeBench 上的性能略有提升,从 42.6% 提升到 46.3%。然则,在手动搜检较小模子(小于 32B 的模子)的输出时,团队发现它们不竭生成肖似实质,从而截止了它们的有用性。
数据混杂很伏击。团队当先使用 Numina 数据集(由 STILL-2 提供)中的 3-4K 个数常识题检修 32B 模子,AIME24 的准确率从 16.7% 显赫提升到 43.3%。然则,将 APPs 数据集生成的编程数据纳入检修历程时,AIME24 的准确率下跌到 36.7%。可能意味着,这种下跌是由于数学和编程任务所需的推理时势不同。
编程推理广泛触及出奇的逻辑步地,如模拟测试输入或里面实践生成的代码,而数常识题的推理经常更为径直和结构化。为了措置这些互异,团队使用 NuminaMath 数据谈判具有挑战性的数常识题和 TACO 数据谈判复杂的编程任务来丰富检修数据。这种平衡的数据混杂使模子在两个限制齐发扬出色,在 AIME24 上收复了 43.3% 的准确率,同期也提升了其编程智商。
与此同期,也有商酌者示意了怀疑:


对此宇宙若何看?宽饶在挑剔区商榷。
参考连气儿:https://www.reddit.com/r/LocalLLaMA/comments/1hys13h/new_model_from_httpsnovaskyaigithubio/古代家庭伦理小说